Если вы запутались в том, какую модель ChatGPT вы используете — GPT-4o, GPT-4.1, GPT-4 Turbo или что-то вроде «o3-mini-high», — вы не одиноки. Система именования моделей OpenAI стала настолько хаотичной, что даже разработчики и инсайдеры ИИ теряются в догадках. А теперь и сама компания признала наличие проблемы.
Имена моделей OpenAI — это беспорядок — и даже Сэм Альтман с этим согласен
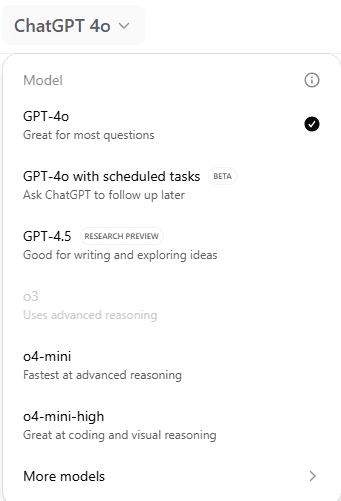
Растущая проблема именования
По мере того как OpenAI продолжает выпускать новые модели ИИ с несколько иными возможностями и ценовой структурой, их именование превратилось в алфавитный суп из номеров полуверсий и расплывчатых суффиксов вроде «mini», «turbo», «pro», «nano» и «o». Без последовательной и интуитивно понятной структуры практически невозможно определить, какая модель самая мощная, самая доступная или самая современная.
Например:
| Имя модели | Ключевое свойство/использование |
|---|---|
| GPT-4.1 | Улучшение по сравнению с GPT-4, но не GPT-5 |
| GPT-4 Turbo | Более быстрый и дешевый вариант GPT-4 |
| GPT-4o | Версия «Omni», ориентированная на мультимодальный ввод |
| o3-mini | Маленькая, быстрая модель с ограниченным контекстным окном |
| o4-mini-high | Усовершенствованная версия o4-mini, подробности неясны |
Даже опытным пользователям остается гадать, что означает каждое название в плане производительности, размера и функциональности.
Альтман и OpenAI говорят, что исправят это
Путаница достигла такой степени, что генеральный директор OpenAI Сэм Альтман (Sam Altman) публично признал наличие беспорядка. В недавнем сообщении он сказал, «Как насчет того, чтобы исправить именование наших моделей к этому лету, а до тех пор у всех будет еще несколько месяцев, чтобы посмеяться над нами (чего мы вполне заслуживаем)?» Это открытое признание отражает, насколько глубокий резонанс вызвала эта проблема у пользователей всех стран.
Даже Кевин Вейл, главный директор по продуктам OpenAI, во время своего выступления в подкасте назвал эту концепцию именования «абсолютно отвратительной». Очевидно, что внутри и за пределами компании сложилось единое мнение, что нужно что-то менять.
Почему это важно
Именование может показаться незначительным вопросом, но оно имеет реальные последствия:
- Для разработчиков: Когда API и документация не дают четкого определения возможностей по имени, это создает дополнительные трудности в рабочих процессах.
- Для предприятий: Это усложняет выбор подходящей модели для продукта или инструмента, влияет на бюджеты и производительность.
- Для повседневных пользователей: Это приводит к путанице в понимании того, с чем они взаимодействуют и какие функции доступны.
Плохое именование также создает маркетинговую проблему. Когда модели с серьезными техническими различиями обозначаются практически одинаково, OpenAI упускает возможность подчеркнуть достигнутые ими успехи — например, снижение задержки, улучшение мультимодального восприятия или улучшение памяти.
Лучшее будущее для названий моделей ИИ?
Согласно сообщениям, OpenAI планирует упростить линейку своих продуктов с предстоящим запуском GPT-5. По слухам, GPT-5 будет более унифицированным под капотом и будет включать в себя автоматический выбор модели, когда система за кулисами решает, какую версию использовать, основываясь на вашем запросе. Это может избавить пользователей от необходимости вообще задумываться о названии модели — такой подход отражает взаимодействие потребителей с повседневными технологиями, такими как поисковые системы или цифровые ассистенты.
Тем не менее, пока этот переход не произойдет, пользователи будут вынуждены ориентироваться в беспорядочном ландшафте почти одинаковых названий моделей, в которых отсутствует четкая иерархия.
По мере развития ИИ именование моделей может показаться незначительной деталью, но это важнейшая часть обеспечения доступности, надежности и использования мощных инструментов в масштабе. Пока OpenAI не выполнит свое обещание навести порядок в этом хаосе, сообщество будет продолжать шутить, вентилировать и догадываться о том, как пройти через суп из версий.
Основные выводы
- Названия моделей ChatGPT теперь трудно понять большинству людей.
- Путаница в названиях затрагивает как обычных пользователей, так и экспертов.
- Улучшение наименования позволило бы всем быть в курсе изменений.
Расшифровка системы именования моделей в ChatGPT
В последние годы названия моделей искусственного интеллекта OpenAI становятся все более сложными, что приводит многих пользователей в замешательство. С каждым новым выпуском ChatGPT и других крупных языковых моделей становится все труднее различать возможности и особенности каждой версии.
Эволюция названий моделей
OpenAI начинал с простых названий, таких как GPT, GPT-2 и GPT-3. Эти ранние модели следовали четкой схеме. По мере развития технологии их количество увеличивалось.
После GPT-3 все стало не так однозначно. OpenAI выпустила такие модели, как GPT-3.5, а затем GPT-4. Недавно в системе появились имена, включающие комбинацию букв и цифр — например, «o1″, — которые многие пользователи считают запутанными.
Сэм Альтман, генеральный директор OpenAI, даже пошутил, что компания должна «исправить» свои названия к лету 2025 года, потому что людям было трудно следить за обновлениями. Отказ от простых порядковых номеров усложнил для многих понимание того, что предлагает каждый релиз и как он сопоставляется с другими версиями. О путанице говорят на форумах и в социальных сетях: пользователи часто не могут определить разницу между моделями по одному лишь названию. Подробнее о путанице в названиях моделей OpenAI.
Ключевые различия между версиями моделей
Каждый основной выпуск ChatGPT вносит изменения в производительность, понимание и инструменты безопасности. Например, GPT-3 улучшил генерацию текста, а GPT-4 предложил более сильные рассуждения и более широкие знания.
Раньше пользователи могли по номеру версии догадаться о характеристиках или возрасте модели. Новая система наименований, включающая менее очевидные элементы, такие как маленькие буквы («o1» или «o4»), дает мало подсказок об усовершенствованиях или предполагаемом использовании.
Эти модели могут отличаться по скорости, стоимости, точности или поддержке новых плагинов. Ключевые обновления могут быть понятны только из технической документации, а не из названия модели. Это затрудняет пользователям выбор подходящей технологии ИИ для своих нужд без проверки подробных примечаний к выпуску или обзоров.
Распространенные ошибки пользователей
Многие пользователи считают, что нынешний подход OpenAI к наименованию моделей неясен. Давние пользователи, разработчики ИИ и новые клиенты с трудом отличают одну модель от другой, потому что названия больше не отражают очевидных изменений или улучшений.
На многих форумах сообщества пользователи сравнивают последние соглашения OpenAI по именованию с «лабиринтом» или «кодом». Часто задаются вопросы вроде «Какая разница между GPT-4 и o1?». Некоторые даже говорят, что новая система позволяет легко выбрать неправильную модель по ошибке.
- Основные моменты, вызывающие путаницу, включают:
- Отсутствие четкого порядка или последовательности в названиях
- Буквы или дополнительные символы без смысла
- Сложность идентификации обновлений версий
В связи с этим многие надеются, что OpenAI изменит свой подход и в будущем упростит понимание больших версий языковых моделей. Вы можете увидеть больше примеров обсуждения этих проблем на форуме разработчиков OpenAI и в других сообществах пользователей.
Воздействие на пользователей и разработчиков
Изменения в системе наименований ChatGPT привели к путанице. Это создает препятствия для пользователей, преподавателей и программистов, которые пытаются следить за обновлениями, открывать для себя новые возможности или полагаться на последовательный контекст и учебные ресурсы.
Препятствия для обучения и образования
Преподавателям и студентам теперь трудно следить за обновлениями или выбирать подходящую версию ChatGPT для своих уроков. Многие руководства или инструменты ссылаются на устаревшие названия, что делает неясным, какая модель поддерживает те или иные функции.
Это может быть сложно для тех, кто создает учебные программы или учебные материалы. Внезапные изменения в названиях или неясные обозначения моделей означают, что ресурсы могут устареть в одночасье. Последовательность в именовании — ключ к эффективному обучению.
Некоторым учителям приходится тратить дополнительное время на объяснение новых правил именования, вместо того чтобы сосредоточиться на предмете. Учащимся становится трудно практиковаться с правильными инструментами.
| Выпуск | Влияние |
|---|---|
| Изменения в названии | Устаревшие инструкции и путаница |
| Неясные версии | Более сложное планирование уроков |
| Неопределенность характеристик | Сложный выбор инструмента |
Проблемы интеграции и программирования
Разработчики сталкиваются с дополнительными трудностями при интеграции ChatGPT в свои приложения. Каждое обновление модели приносит новые имена, ломая существующий код или приводя к ошибкам. Руководства по интеграции могут быстро устареть.
Сценарии автоматизации могут не сработать, если они вызывают старое имя модели. В этом случае программистам приходится более тщательно отслеживать обновления, тратя время на обслуживание вместо создания новых функций.
Пользовательские инструкции иногда игнорируются в новых моделях, о чем сообщают пользователи после обновлений. Это означает, что разработчики должны заново проанализировать, как использовать пользовательские настройки, и заново протестировать все поведение. Некоторые пользователи на форумах рассказывают о проблемах интеграции после обновлений.
Двусмысленность в обнаружении полезностей и функций
Частые или неясные изменения названий затрудняют понимание того, что может делать каждая модель. Документация и списки функций часто не успевают за каждым изменением названий.
Пользователи могут не понимать, что новые модели предлагают другие контекстные ограничения, инструменты или производительность. Некоторые не замечают улучшений, потому что именование не отражает добавленные функции или изменившиеся полезные свойства. Это приводит к тому, что время, потраченное на изучение моделей, уходит на догадки.
Люди, полагающиеся на ChatGPT при выполнении таких задач, как обобщение, кодирование или анализ данных, иногда используют менее функциональные версии. Они могут не заметить этого просто потому, что название модели больше не указывает на ее сильные стороны, что приводит к упущенным возможностям улучшить рабочий процесс и результаты.
Более широкие последствия для экосистемы искусственного интеллекта
Путаница в системе наименований ChatGPT может привести к неопределенности в области искусственного интеллекта. Это влияет на то, как пользователи, компании и исследователи понимают и принимают новые модели.
Последствия для доверия и принятия
Четкие названия моделей помогают людям понять, что может делать инструмент и каковы его ограничения. Когда названия становятся запутанными, пользователи и предприятия могут начать сомневаться в том, какую версию они используют, насколько она актуальна и соответствует ли она их потребностям.
Крупные компании, такие как Microsoft, полагаются на знание деталей и сильных сторон каждой модели искусственного интеллекта, прежде чем использовать их в Office, Bing или Copilot. Если пользователи не смогут определить, какая модель ChatGPT работает под капотом, доверие к этим сервисам может упасть.
Нечеткое именование может привести к нерешительности при внедрении новых инструментов. Пользователи могут отложить переход на новейшую модель, опасаясь, что она не будет соответствовать их потребностям или нарушит старые рабочие процессы. В результате инновации в области машинного обучения могут не раскрыть весь свой потенциал.
Реакция представителей больших технологий и научных кругов
Большие технологии Такие компании, как Microsoft, Google и Amazon, хотят прозрачности. Если в системе наименований не хватает ясности, они могут потребовать от OpenAI и подобных компаний более подробных объяснений. Им необходимо убедиться, что модели ИИ работают так, как ожидается, и остаются актуальными.
Такие учебные заведения, как MIT и другие университеты, зависят от последовательного именования моделей для исследований и курсовых работ по машинному обучению. Если студенты или ученые не могут соотнести свою работу с конкретными версиями моделей, результаты исследований могут стать ненадежными. В научных работах может возникнуть проблема сопоставления результатов, а на занятиях могут использоваться устаревшие или неоднозначные инструкции.
Такая неясность снижает ценность сотрудничества в отрасли и замедляет прогресс. И промышленности, и научным кругам нужны общие стандарты, чтобы искусственный интеллект оставался открытым и полезным для всех.
Влияние на юридические консультации и человеческие ценности
Идентификация модели может повлиять на юридические вопросы. Если именование неясно, юристам может быть трудно понять, какая модель приняла то или иное решение или рекомендацию. Это создает проблемы при разрешении споров или проверке соблюдения правил.
Юрисконсульты, работающие с крупными технологическими компаниями, сталкиваются с дополнительными трудностями при обеспечении соответствия и подотчетности. Государственные регулирующие органы могут запросить записи о том, какие версии моделей использовались во время ключевых событий.
Человеческие ценности, такие как справедливость и безопасность, также находятся под угрозой. Если пользователи не могут подтвердить, какая модель дала тот или иной результат, трудно проверить решения на предмет предвзятости, ошибок или вредных последствий. Таким образом, организациям сложнее убедиться в том, что искусственный интеллект соответствует общественным ожиданиям и требованиям законодательства. Более подробную информацию о прозрачности и ее более широком влиянии на доверие к ИИ и его внедрение можно найти на сайте ScienceDirect.
Сравнение с другими конвенциями именования ИИ
Многие области ИИ сталкиваются с аналогичными проблемами именования, такими как неясные обозначения и запутанная нумерация. Эти проблемы могут повлиять на понимание, доверие и даже безопасность искусственного интеллекта.
Уроки самоуправляемых автомобилей и чатботов
Компании, производящие самоуправляемые автомобили, такие как Waymo и Tesla, используют более прямолинейные названия для функций самостоятельного вождения. Например, Tesla называет свою систему «Автопилот», что просто и легко запоминается. Новые обновления нумеруются или получают четкие названия, например «Full Self-Driving Beta». Это помогает и потребителям, и экспертам отслеживать различные версии и функции без особой путаницы.
Чат-боты, в том числе созданные Google и Microsoft, часто следуют прямолинейным названиям. Google Assistant и Copilot от Microsoft используют понятные, фирменные названия вместо кодов или номеров версий. В отличие от них, названия моделей ChatGPT, такие как «o3» или «o4-mini-high», создают путаницу, что подчеркивают многие пользователи, сравнивающие их с запутанными названиями моделей ИИ в инструментах OpenAI.
Придерживаясь прямых названий и последовательной нумерации, пользователи других областей, таких как технологии самостоятельного вождения и цифровые ассистенты, легче понимают суть обновлений.
Роль нейронных сетей и грамматики
Модели нейронных сетей часто называют, используя термины из лингвистики — «трансформаторы», «кодировщики» или «декодировщики» — для описания их функций. Некоторые компании добавляют «умный штрих», включая в названия слова, связанные с языком, или грамматические подсказки. Например, модель BERT от Google расшифровывается как «двунаправленные кодирующие представления из трансформаторов».
Однако тенденция к сокращению кодов, смешанной капитализации и случайным числам (например, «o4-mini-high») не позволяет публике догадаться, что делает эта модель или как она улучшена по сравнению с предыдущими версиями. Простые грамматические или описательные термины помогают людям понять интеллект и назначение модели по сравнению с менее описательными названиями, которые скрывают роль нейронной сети или ее модернизацию.
Таблица примеров
| Имя модели | Стиль | Ясность |
|---|---|---|
| БЕРТ | Описательный | Высокий |
| Автопилот (Tesla) | Функциональные | Высокий |
| o4-mini-high | Кодировка | Низкий |
Риски запутывания и кражи интеллектуальной собственности
Запутанные системы наименований создают более серьезные риски, чем просто недопонимание. Когда модели ИИ трудно отличить друг от друга, недобросовестным субъектам становится проще копировать, переупаковывать или красть идеи под новыми именами. Кроме того, при возникновении проблем может оказаться сложнее отследить, какая версия нейросети отвечает за те или иные действия.
В индустрии самодвижущихся автомобилей четкие названия снижают вопросы ответственности и облегчают определение того, какой интеллект или функции содержит каждый продукт. Для чат-ботов и моделей, подобных ChatGPT, отсутствие или плохое применение грамматики и нечеткие названия могут скрывать важные детали безопасности, позволяя хакерам использовать пробелы в системе наименований.
Генеральный директор OpenAI сам признал эту проблему, пообещав «исправить» путаницу в названиях моделей, чтобы защитить продукт и его пользователей от ошибок и потенциальных краж.
Часто задаваемые вопросы
Названия и версии моделей ChatGPT часто сбивают с толку как новых, так и давних пользователей. Система наименования этих моделей ИИ часто меняется, и без четкого руководства следовать ей может быть сложно.
Чем обоснованы соглашения об именовании, используемые для новых моделей ChatGPT?
Названия часто отражают этапы внутренней разработки или уникальные особенности. Некоторые названия могут включать буквы, цифры или кодовые имена, которые не всегда понятны широкой публике. Поскольку обновления выходят быстро, причины, лежащие в основе некоторых названий, редко становятся достоянием общественности или подробно объясняются.
Как система версий моделей ChatGPT соотносится с их возможностями и улучшениями?
Номера версий иногда увеличиваются с большими обновлениями, которые добавляют новые возможности или исправляют крупные проблемы. Однако не все мелкие обновления получают четкие номера версий. Из-за такого несоответствия трудно отследить, что на самом деле предлагает каждая модель по сравнению с предыдущей.
Можете ли вы объяснить различия между разными поколениями моделей ChatGPT?
Каждое поколение вносит изменения в скорость, точность или понимание вопросов. Например, некоторые поколения гораздо лучше справляются с длинными разговорами, в то время как другие сосредоточены на более быстрых ответах или меньшем количестве ошибок. Эти улучшения часто перечисляются в анонсах технологий, но сами названия не всегда делают эти изменения очевидными.
Существует ли полное руководство, позволяющее понять последовательность обновления моделей ChatGPT?
Онлайн-сообщества и новостные сайты иногда публикуют руководства по моделям ChatGPT и их обновлениям. Однако трудно найти единый официальный источник со всеми изменениями и подробностями именования. Большая часть информации поступает из разрозненных сообщений или со справочных форумов.
Какие ключевые факторы влияют на название новых моделей ChatGPT?
Разработчики учитывают внутренние системы кодирования, результаты исследований и маркетинговые потребности. Иногда модели получают названия в связи с техническими обновлениями. В других случаях названия выбираются для запуска продукта, но они могут не иметь шаблона, что вносит дополнительную путаницу.
Как пользователи могут отслеживать обновления моделей ChatGPT и их соответствующие возможности?
Следить за обновлениями обычно означает следить за форумами, новостными порталами AI или официальными записями в блогах. Пользователи также могут проверять обсуждения в сообществе на предмет сообщений о новых версиях и возможностях. Не существует единой, надежной панели, на которой всегда можно найти все обновления, как только они появляются.